AI Agent Costs Are a Black Box, So I Built AgentMeter
AgentMeter tracks AI agent costs in GitHub Actions, bringing transparency to Claude, Codex & GitHub Agentic Workflows spending

Software engineering is undergoing a fundamental shift. We're not talking about another framework or cloud service—this is about how we write code itself. AI agents are moving from experimental toys to production infrastructure. Take GitHub Agentic Workflows (gh-aw), developed by GitHub Next and Microsoft Research. It lets you write repository automation in markdown, running AI agents like Claude, Codex, or Copilot inside GitHub Actions with proper guardrails and sandboxed execution. Teams are using it right now to auto-implement issues, review PRs, maintain documentation, and analyze CI failures—triggered by events or running on schedules.
The trajectory is clear: agentic developer workflows are becoming standard CI/CD components. Just like we automated testing and deployment, we're now automating implementation and review. The infrastructure is mature, the security models exist, and the results are measurable. But there's one glaring problem nobody wants to talk about.
The Part Where We Pretend Money Doesn't Exist
Here's what bothers me about the current state of AI-powered development: every agent run costs money, but good luck figuring out how much. A single feature implementation can spawn multiple agent runs—implement the initial code, review it, run end-to-end tests, fix issues, retry. Each step burns tokens. Thousands of them. But where exactly do you go to see what that costs?
Check Anthropic's console? You'll find aggregate daily API spend with zero attribution to specific issues, PRs, or workflows. It's like getting a credit card statement that just says "You spent $847 on stuff." GitHub Actions? Sure, it shows runner minutes, but nothing about LLM token usage. The agent run itself is a complete black box—Claude Code and Codex don't surface token counts as step outputs by default.
You can't answer basic questions like "How much did implementing issue #47 cost?" or "Are our automated PR reviews worth the token spend?" or "Why did our AI bill double last month?" You're flying completely blind. For individual developers paying Anthropic out of pocket, this is annoying. For teams with 20+ engineers triggering agents on every PR, it's a legitimate operational problem.
The irony is thick. We've built sophisticated tooling to track every millisecond of API latency, every byte of memory usage, every cent of AWS spend. But when it comes to AI agents—the most expensive part of modern development workflows—we just shrug and hope for the best. AI is eating software development, but apparently nobody thought to build the receipts.
Building the Receipt Layer
I got tired of guessing, so I built AgentMeter. It's two pieces that work together to solve this visibility problem.
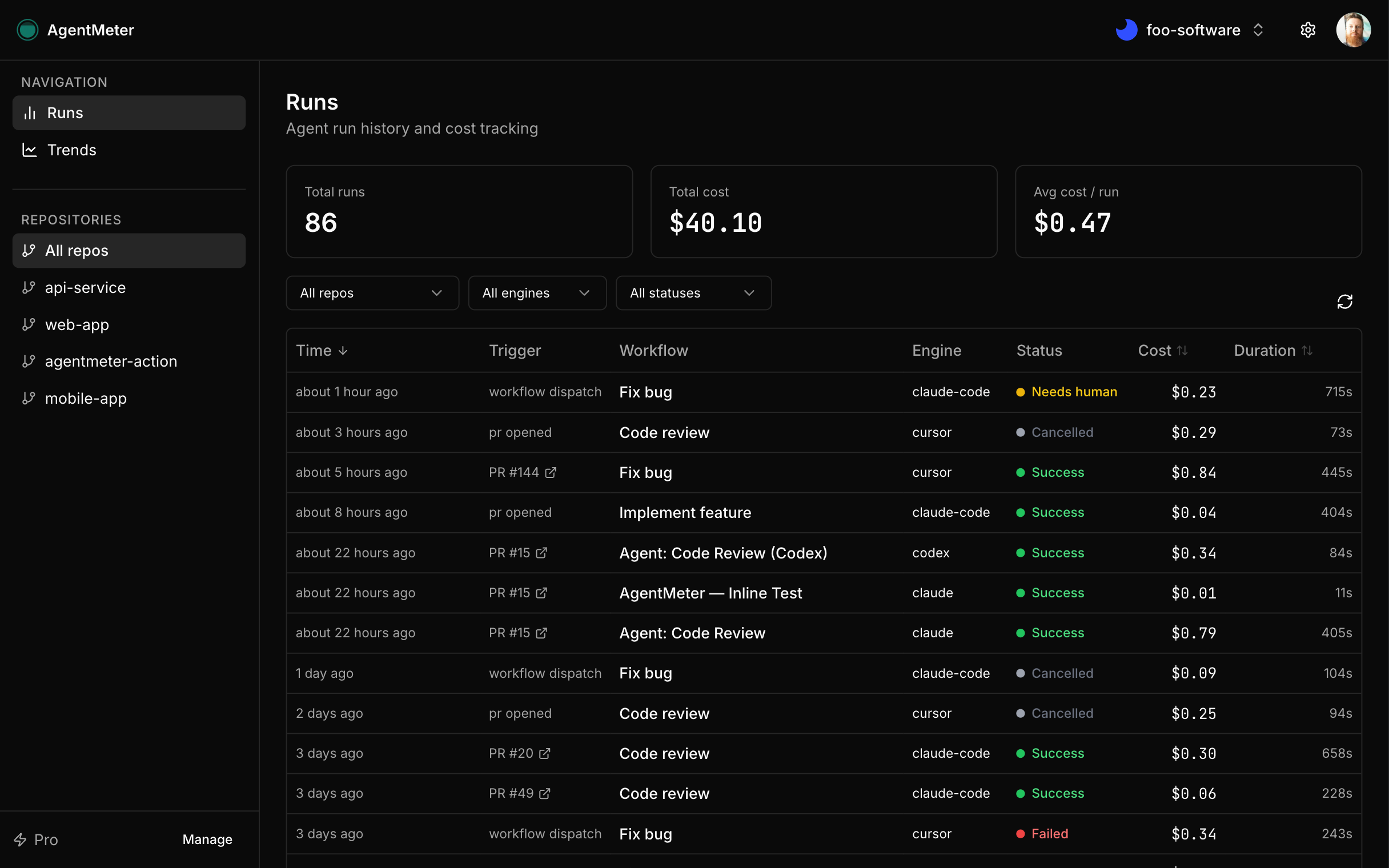
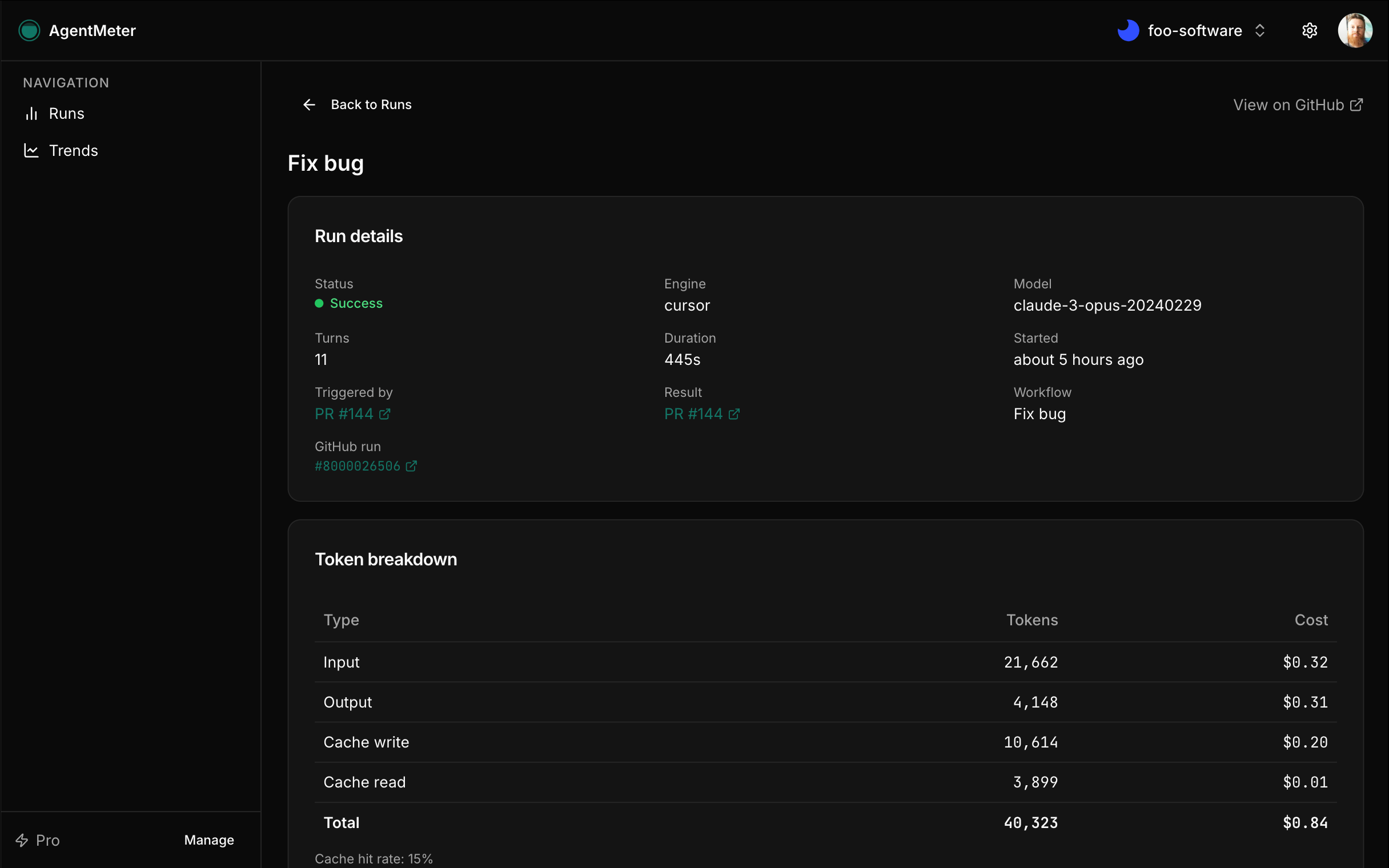
First, there's AgentMeter itself—a GitHub App you install on your org or personal account. It gives you a dashboard at agentmeter.app where every agent run shows up with full details: token counts (input, output, cache read/write), cost in actual dollars, duration, status, and which issue or PR triggered it. The app automatically posts a cost summary comment on PRs and issues after each run, so the information lives right where developers are working. You get trends over time, budget alerts, team access controls. Free tier covers one repository, Pro unlocks unlimited.
Second, there's the AgentMeter Action—a GitHub Action that does the actual tracking. You drop it into any existing workflow, right after your agent step. It's literally three lines of YAML. Works with Claude Code, Codex, and GitHub Agentic Workflows. The action never fails your workflow—all errors surface as warnings because cost tracking shouldn't break your builds.
The design principle was zero friction. You should be able to add cost visibility to an existing workflow in under five minutes without touching your agent configuration. Here's what it looks like for Claude Code:
steps:
- uses: anthropics/claude-code-action@v1
id: agent
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: "Implement the feature described in this issue"
- uses: agentmeter/agentmeter-action@main
if: always()
with:
api_key: ${{ secrets.AGENTMETER_API_KEY }}
status: ${{ steps.agent.outcome }}
model: claude-sonnet-4-5
input_tokens: ${{ steps.agent.outputs.input_tokens }}
output_tokens: ${{ steps.agent.outputs.output_tokens }}
cache_read_tokens: ${{ steps.agent.outputs.cache_read_tokens }}
cache_write_tokens: ${{ steps.agent.outputs.cache_write_tokens }}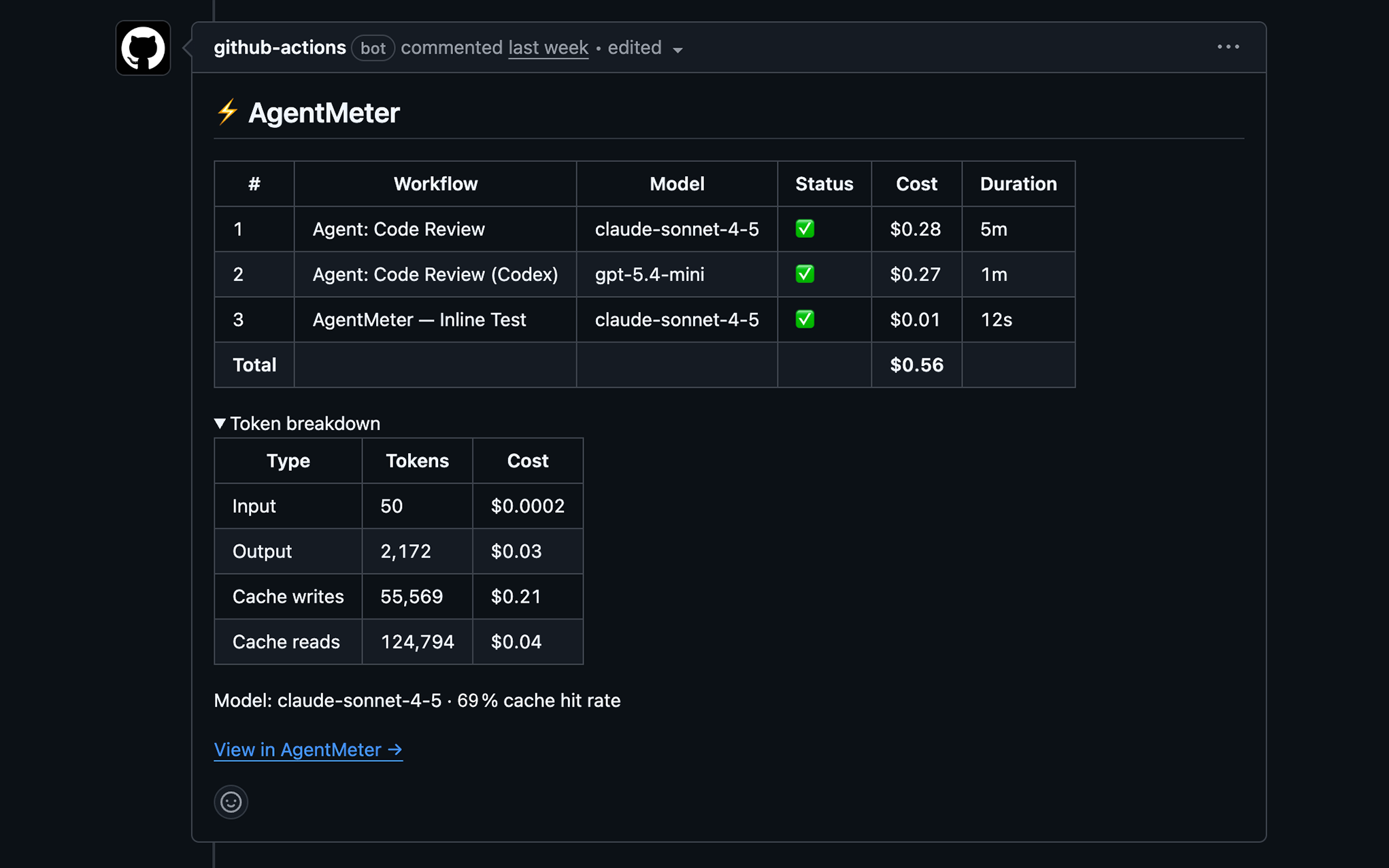
For GitHub Agentic Workflows, which run in their own workflows, there's a companion mode that hooks into the workflow_run event:
# .github/workflows/agentmeter.yml
on:
workflow_run:
workflows:
- "Agent: Implement Issue"
- "Agent: Code Review"
types: [completed]
jobs:
track:
runs-on: ubuntu-latest
permissions:
actions: read
issues: write
pull-requests: write
steps:
- uses: agentmeter/agentmeter-action@main
with:
api_key: ${{ secrets.AGENTMETER_API_KEY }}
engine: claude
model: claude-sonnet-4-5
workflow_run_id: ${{ github.event.workflow_run.id }}That's it. No SDK to integrate, no agent code to modify. The action extracts token counts from workflow artifacts or API responses and sends them to AgentMeter. You get instant visibility into what each run actually costs.
Why Token-Level Visibility Matters
Once you start seeing the numbers, patterns emerge quickly. That innocent-looking "review this PR" prompt? It might be consuming 50,000 input tokens because it's including the entire codebase context. Those retry loops when tests fail? Each one costs as much as the original implementation. Cache tokens can cut costs by 90% for repeated operations, but only if you know they're being used.
This isn't about penny-pinching. It's about making informed decisions. Maybe those automated PR reviews are worth $2 each because they catch real issues. Maybe they're not. Maybe certain types of issues cost 10x more to implement than others. Maybe your prompts are including unnecessary context. Without data, you're just guessing.
For teams running agents on every PR, every issue, every deployment—this adds up fast. A 20-person engineering team can easily burn through thousands of dollars per month in agent costs. That's real money that needs real accountability. AgentMeter provides that accountability without adding friction to the development process.
The Reality of Building in a Greenfield Category
Here's something worth noting: as of March 2026, AgentMeter is the only product providing per-run AI agent cost attribution in GitHub Actions. This is a completely greenfield category. I'm one engineer who got frustrated enough to build this. It's version 1, it's focused on solving one problem well, and it's actively evolving based on how teams actually use agents in production.
The dashboard shows you everything you need: sortable runs feed, cost breakdowns, trend charts, budget tracking. You can filter by repository, model, status, or trigger. Every run links back to the workflow, issue, or PR that spawned it. The cost summary comments on GitHub include just enough detail to be useful without cluttering the conversation.
The AgentMeter Action is open source and designed to be bulletproof. It handles network failures gracefully, validates inputs without being pedantic, and includes detailed debug logging when you need it. The companion mode for gh-aw workflows required some creative artifact parsing, but it works reliably across different agent configurations.
Where This Is All Heading
Let's circle back to the bigger picture. GitHub Agentic Workflows and similar tools are becoming standard parts of software development. When AI agents run on schedules every morning, implementing features, reviewing code, and maintaining documentation, cost accountability isn't optional. It's the same reason we have billing dashboards for AWS, metrics for API usage, and alerts for resource consumption.
The difference is that AI agent costs are variable in ways that traditional infrastructure isn't. A complex feature might cost $20 to implement. A simple bug fix might cost $0.50. Without visibility, you can't optimize, you can't budget, and you can't make rational decisions about where to deploy these powerful but expensive tools.
AgentMeter is the receipt layer for agentic development. It's the missing piece that makes AI-powered workflows sustainable at scale. Sign up at agentmeter.app, add the AgentMeter Action to your workflows, and start seeing what your agents actually cost. Because in a world where AI is writing increasingly more of our code, understanding the economics isn't optional—it's table stakes.